Sistema di Classificazione Binaria mediante Boltzmann Machine
I Sistemi di Raccomandazione trovano applicazione in una casistica estremamente estesa e in crescita vertiginosa. Un caso tipico è quello della previsione di tipo binario: un prodotto, un servizio, un film non ancora provato o fruito, sarà apprezzato o disprezzato dal nostro utente finale, valutato positivamente o negativamente?
Sul web si trovano molti dataset utili a costruire e addestrare un Reccomendation System, il dataset MovieLens reperibile dal sito grouplens.org è uno dei più completi e fa perfettamente al caso nostro. In esso sono contenute le valutazioni di tantissimi film, espresse su una scala di valori che va da 1 a 5 (dove 1 corrisponde a un giudizio estremamente negativo e al capo opposto si colloca il 5 che corrisponde al giudizio migliore possibile). E’ possibile scaricare molti dataset, da quello contenente 20 milioni di valutazioni espresse su 27000 film da 138000 spettatori a quello più leggero contenente solo 100000 valutazioni espresse su 1700 film da 1000 spettatori. Questa ampia disponibilità di dataset di diverse dimensioni permette anche a coloro che sono dotati di macchine non eccezionalmente performanti di esercitarsi e fare valutazioni su vari modelli e algoritmi di apprendimento e diversi tipi di reti neurali.
Il nostro Sistema di Raccomandazione binaria sarà costituito da una Restricted Boltzmann Machine implementata mediante PyTorch. Nella pratica importeremo il dataset, creeremo i Training e Test Set, convertiremo i dati in un array le cui righe saranno gli spettatori e le cui colonne saranno i film e in ultimo li trasformeremo in PyTorch Tensors. Continueremo costruendo il nostro modello di Boltzmann Machine, facendone l’addestramento e verificando il livello di performance sul Test Set. Finalmente saremo in grado di prevedere per ogni spettatore quale potrebbe essere la valutazione (positiva o negativa) per i film che ancora non ha visto.
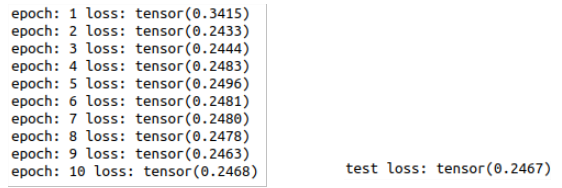
I risultati ottenuti dal nostro modello sono corretti nella misura di 3 previsioni su 4, infatti sia in fase di training che di testing abbiamo ottenuto una loss (calcolata in termini di distanza media) inferiore allo 0.25, come evidenziato nelle figure seguenti.
Nella classe di definizione della Restricted Boltzmann Machine è stato inserito il seguente metodo di predizione:

A questo punto, scelto uno spettatore qualunque dal dataset di Test e presa l’intera lista dei suoi film è stato possibile eseguire il confronto tra i valori reali e quelli stimati. La tabella seguente ne costituisce un esempio:

La prima riga mostra i valori reali e la seconda quelli stimati. I valori reali rappresentati da -1 sono relativi ai film mai visti e recensiti. Si presti attenzione ai valori sulla stessa colonna e immediatamente sottostanti, che rappresentano la raccomandazione circa il film indicato dal numero di colonna,
Dalla tabella si vede che il sistema raccomanda i film 17, 18 e 20 mentre il film 19 non viene raccomandato. I film 21 e 22 risultano già visti ma comunque anche in tale caso il sistema fa una stima corretta.
Può capitare, come si vede nella tabella successiva, che il sistema faccia una stima errata, ma ciò succede una volta su quattro.

Il film numero 95 non è stato particolarmente apprezzato dal nostro spettatore, ma il sistema purtroppo lo raccomanda.