Fraud Detection mediante Sistema Ibrido (SOM + ANN)
Immaginiamo che una banca ci abbia dato l’incarico di individuare le frodi potenziali mediante l’utilizzo di un dataset contenente le informazioni relative ai clienti che hanno richiesto una carta di credito di tipo avanzato. In buona sostanza le informazioni di cui disponiamo sono quelle provenienti dal form che i clienti compilano al momento della richiesta della carta di credito. Il nostro obiettivo è fornire alla banca la lista dei clienti che con buona probabilità hanno “barato”.
Per individuare i problemi potenziali ci serviremo di una tecnica Unsupervised, individuando dei pattern specifici all’interno di un database multidimensionale caratterizzato da forti non-linearità.
Il dataset che utilizzeremo è quello dell’Australian Credit Approval presente sull’UCI Machine Learning Repository, come indicato nella figura sottostante
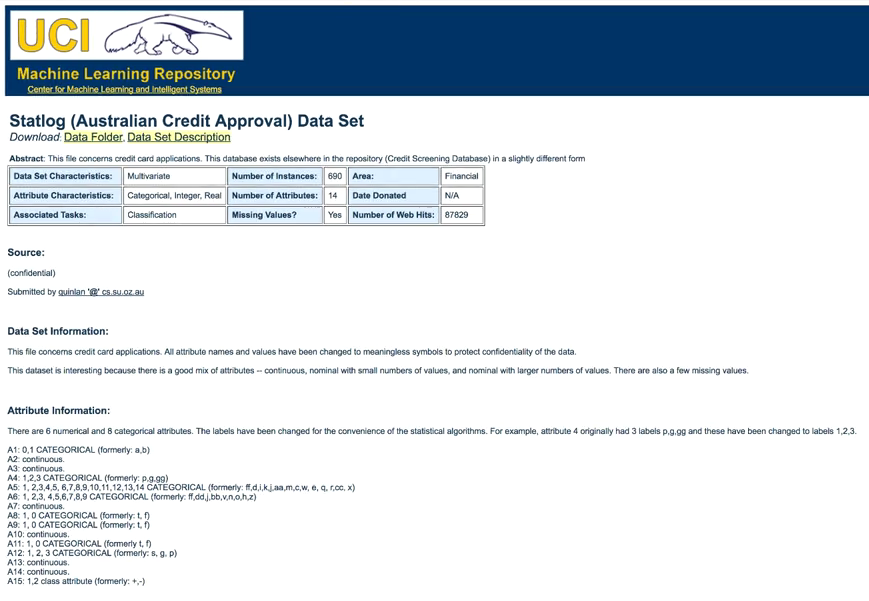
Esso contiene 690 casi e 14 attributi relativi a richieste di carte di credito e come si può leggere nelle informazioni tutti i nomi e i valori degli attributi sono stati modificati al fine di salvaguardare la confidenzialità. Alcune variabili sono numeriche e altre sono categoriche, all’interno di tale mix si nascondono i pattern che possono portare alla individuazione di eventuali frodi.
Tecniche di clustering possono sicuramente essere di grande aiuto nella determinazione dei gruppi di interesse, ma l’obiettivo che ci siamo prefissati e’ leggermente più ambizioso perché vogliamo fornire alla ipotetica banca la lista dei clienti ordinata per probabilità di frode. In altre parole il nostro obiettivo è ordinare i clienti secondo il livello della probabilità che abbiano mentito.
Di seguito si riporta per semplicità il dataset con tutti i suoi attributi.
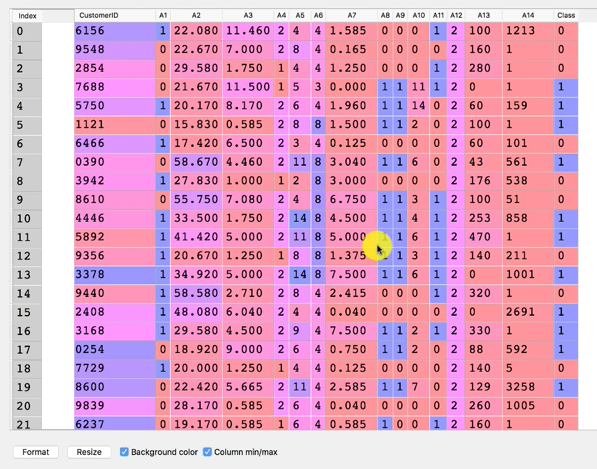
Mediante la costruzione di una Self Organizing Map (SOM) e una sua rappresentazione grafica secondo un codice di colori (bianco alta probabilità di frode, nero bassa – quadrato verde carta di credito concessa, cerchietto rosso carta di credito rifiutata) individueremo visivamente tutte le frodi potenziali. Il risultato ottenuto sarà qualcosa del genere:
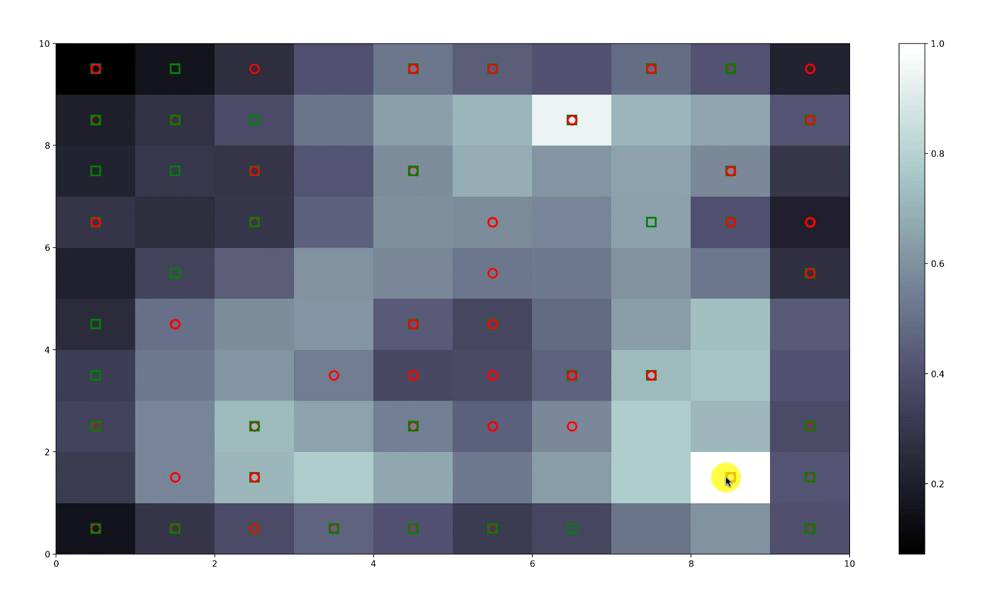
A questo punto saremo in grado di individuare le frodi potenziali, per esempio nella figura è evidenziata una casella bianca (altissima probabilità di frode) in cui ricadono casi di clienti ai quali sono state assegnate (quadrato verde) e non assegnate (cerchietto rosso) delle carte di credito, ovviamente una grande attenzione andrà riservata a coloro che hanno ottenuto la carta di credito.
Una volta ottenuta la lista dei potenziali clienti la utilizzeremo per costruire la variabile dipendente del modello Supervisionato, una Rete Neurale Artificiale standard, che ci servirà a calcolare il grado di probabilità della frode.
Dopo aver quindi costruito la nostra ANN e averne completato l’addestramento utilizzando come features la lista degli attributi del dataset iniziale, saremo in grado di produrre una lista di clienti ordinata per probabilità di frode come quella rappresentata di seguito. Tale lista sarà il risultato ricercato e potrà essere consegnata alla banca che effettuerà i controlli e le verifiche del caso.
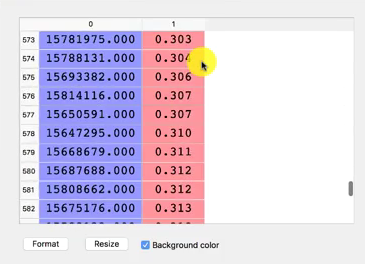
Il dataset utilizzato a fini didattici contiene solamente 690 casi per cui la Rete Neurale Artificiale da noi impiegata non produce risultati particolarmente performanti, ovviamente lo stesso metodo eseguito con un dataset molto più corposo e un numero di epoche adeguato porterebbe a risultati assolutamente degni di nota.